フットボール・データアナリティクス:得点期待値に関する新指標「xG」についての解説
2019.02.07 written by Temma H.
昨シーズン(2017/18)からヨーロッパではMatch Of The DayやSkyなどのメインストリームでも「xG」という新たな指標が用いられるようになりました。Expected
Goalsの略であるその指標は得点の期待値を指し、今なお発展を遂げています。分析界隈ではその存在は有名ですが、整数ではなく少数点以下があるこのデータはコミュニティ外の一部の人々を混乱させています。今回の記事では普段データに触れていない人でも最低限理解できるように、日本代表戦を例にとってxGプロットの見方を説明し、そこからデータ分析を目指す人々や実際のアナリストがxGモデルを自分で実装する道しるべにもなるような内容になればと思います。
xGとは
サッカーとはゴールの数を競うスポーツであり、ゴールを奪うためのアクションがシュートです。そして従来のスタッツとしてシュート本数(さらに枠内シュート本数)が用いられてきました。しかし全てのシュートが同じ価値を持つわけではありません。ゴールから近ければ近い方が得点の可能性が高まります。ボールとゴールの間に敵がいない方が得点しやすくなります。そういったことを考慮して(パラメータに組み込んで)、ある特定の状況でのシュートがゴールになる確率を求めます。
xGは基本的にチャンスの質を評価する指標です。シュートを打った選手の技術的な能力やシュートの質は無視するのが普通です。xGと実際の得点を比較することで、選手やチームの質を評価することができますが、長期的に見ると偏り(ノイズ)は徐々に収束します。
ここで、xGモデルによく用いられるパラメータを紹介しましょう。まずは距離と角度です。データは基本的に直交座標系(xy座標系)で与えられ、それを変換して用います。逆三角関数の知識が必要になります。ヘディングシュートよりも足でのシュートの方が得点の可能性が高まります。次にシュートの前のアクションです。スルーパスやドリブルだと相手を置き去りにできる(パッキングレート)ので得点の確率が高まります。クロスからのシュートは得点の確率が低くなります。こぼれ球については後で別途議論します。またポゼッションの開始位置や縦へのスピード、スコアラインなどもパラメータに組み込むことができます。
サッカーで取得できるデータはイベントデータとトラッキングデータに分類できます。上記のパラメータはイベントデータですが、近年はどんどんトラッキングデータも組み込まれるようになってきました。最先端のxGモデルのパラメータとして、守備圧力度(守備陣のプレッシングの度合い)やシュート明瞭度(ボールとゴールの間の守備陣の人数)、GKのポジショニング(ボールとゴール中心を結ぶ直線からのズレ)などがあります。
Passmaps & xGplot for Betis against Atle´tico. #passmap #xGplot #autotweet pic.twitter.com/GK0p2jqj7j
— Between The Posts (@BetweenThePosts) 2019年2月3日
xG map for Barcelona - Real Madrid pic.twitter.com/JwBXuFtuVF
— Caley Graphics (@Caley_graphics) 2019年2月6日
xGプロットの見方
オランダ人の11tegen11氏を始め、Michael Caley氏、understat.com、infogol.netなど、ヨーロッパトップリーグのxGデータを入手することは簡単です。またAmerican Soccer
Analysisのアナリストにより、メジャーリーグサッカーに関しても豊富なデータが揃っています。こういったデータをもとに筆者もxGプロットを作ってみているので、アジアカップの日本代表を例に取って説明してみましょう。
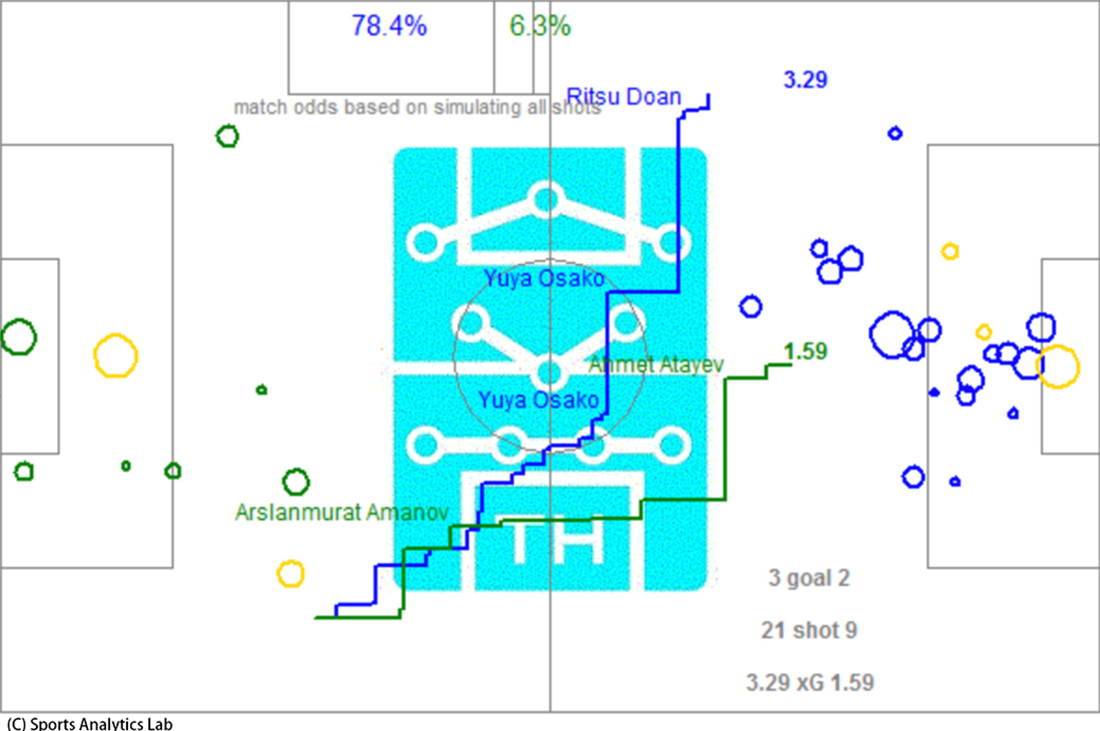
画像:JPN TKM (アジアカップ2019GL 日本vsトルクメニスタン)
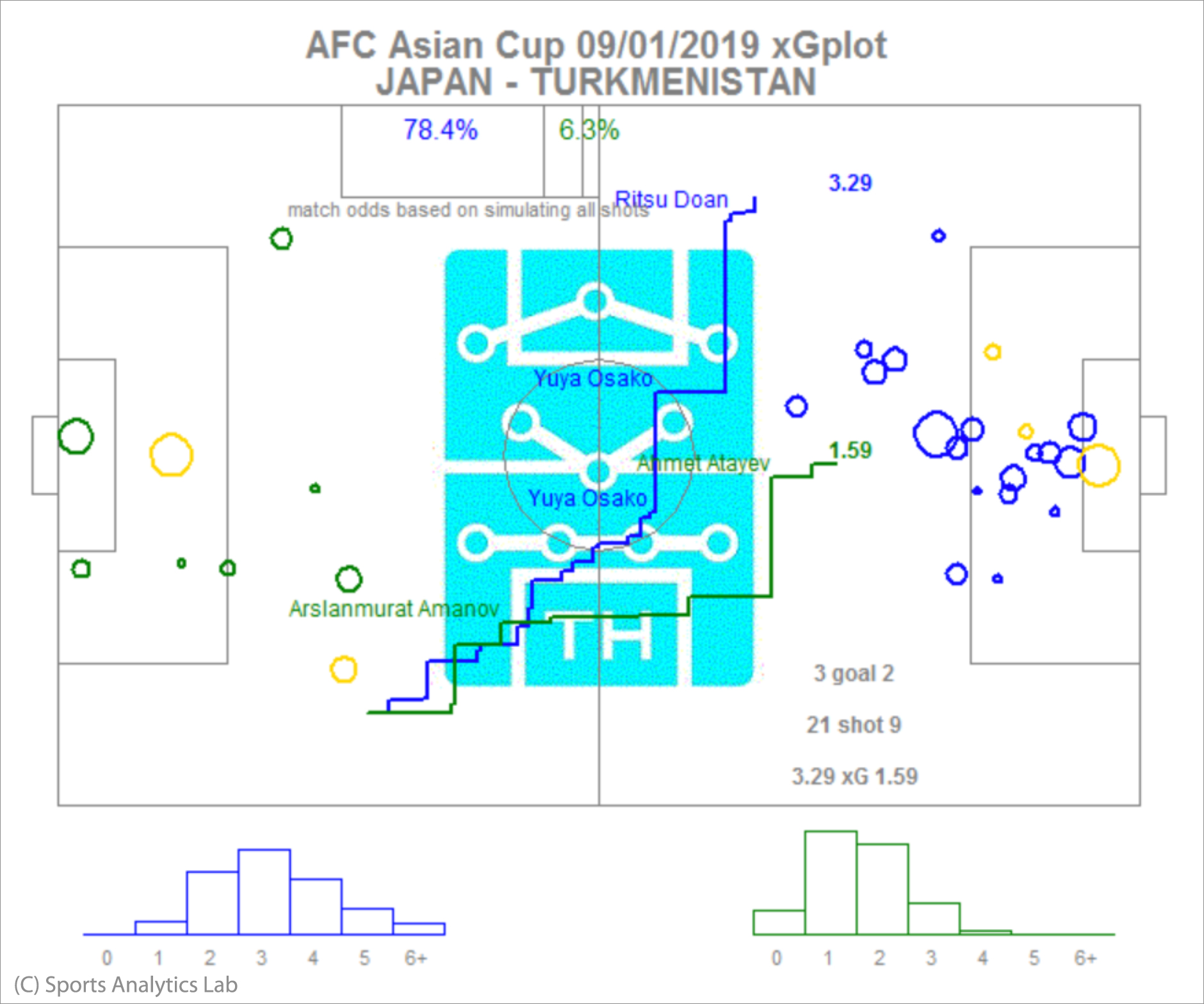
まず両ゴール前の丸の位置はシュート位置を表し、丸の大きさはそのシュートの確率を表します。色が異なる丸はゴールです。そしてそれぞれのチームの得点確率の総和がxGとして載っています。
ピッチ中央の階段状の関数は、それぞれの時間帯での累積(Cumulative)のxGです。縦に上昇している横軸の位置は1試合のうちの時間、縦軸の上昇幅はそのシュートの確率を表します。
左上の試合の最終結果の確率と下の得点数の確率はxGをもとにしたシュミレーションの結果です。各チームが何得点するのが妥当か、どちらのチームが優勢だったのかを示しています。
なおGarry Gelade氏は数字嫌いのためにMPR(Most Probable
Result、最も可能性の高い結果)という指標を提案しています。この指標はxGプロット下部の得点分布で最も可能性が高い得点のことです。例えば日本対トルクメニスタン戦ではxGが3.29-1.59で、MPRは3-1となります。この試合は3-1が最も妥当だったと言われればかなりしっくりくると思います。
画像:OMN JPN (アジアカップ2019GL オマーンvs日本)
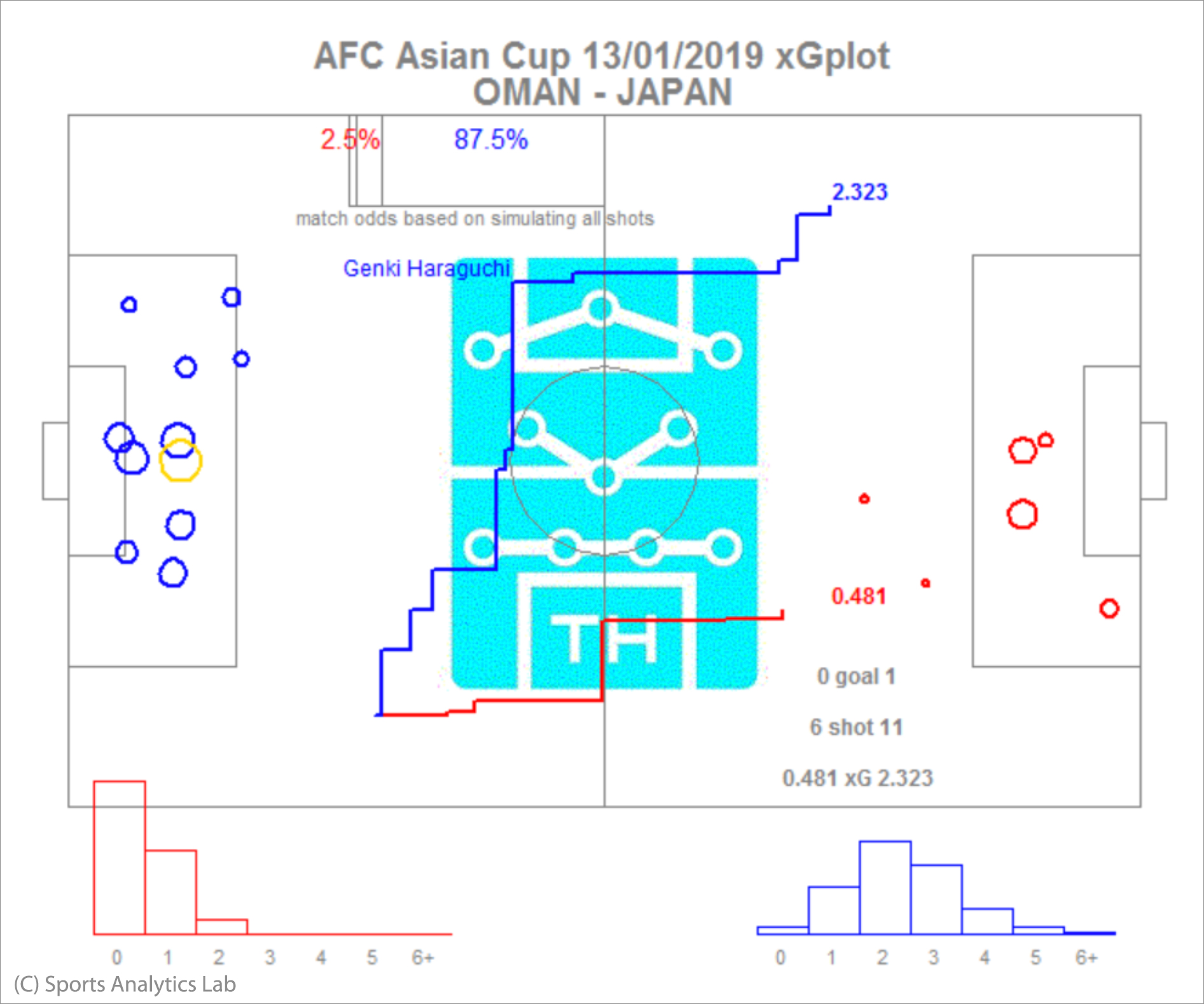
オマーン対日本戦ではxGが0.481-2.323でMPRが0-2です。
画像:JPN UZB (アジアカップ2019GL 日本vsウズベキスタン)
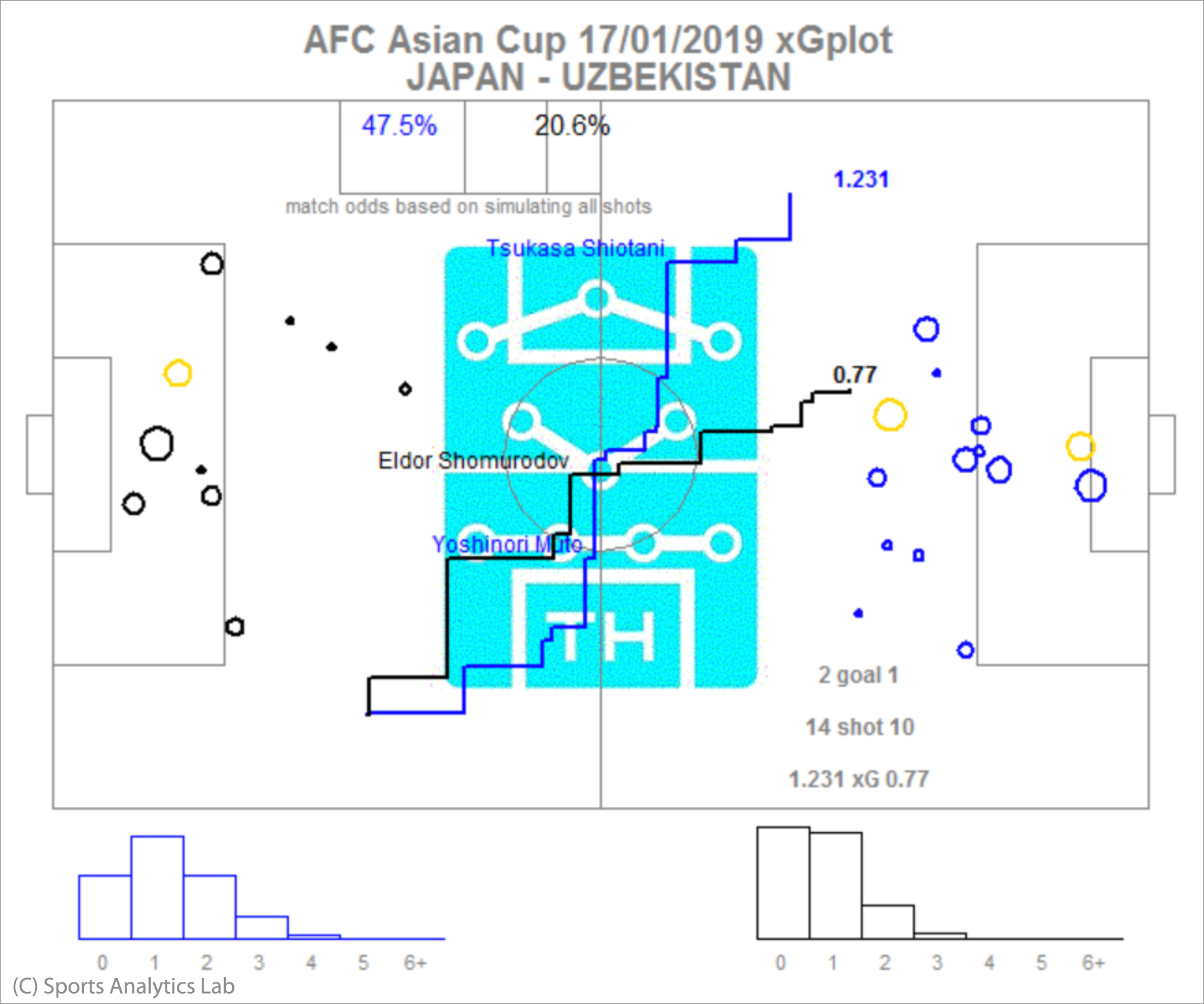
日本対ウズベキスタン戦ではxGが1.231対0.77でMPRが1-0です。
xGの歴史
英語版のWikipediaによると、xGという用語の起源は1993年の人工芝の影響に関する論文に遡ります。その後サッカーやバスケットボール、アイスホッケーなどの競技のデータによって発展を遂げています。
xGが競技に大きな影響を与えた代表例を挙げるとすると、バスケットボールが頭に浮かびます。フリースローを除くと、サークルの内側からのスローは2点、外側からのスローは3点というルールですが、一般的にサークルの少し内側の2ポイントシュートと少し外側の3ポイントシュートでは、得点期待値から3ポイントの方が効率的であることが言われています。それが知られてからは中距離のシュートの割合が減り、リング周辺と3ポイントの割合が増えたようです。
Very cool @Slate #dataviz of #basketball field goal percentage and expected point value: https://t.co/93zdY49v4e pic.twitter.com/oPnp12cxoF
— Mohsen Manesh (@MohsenManesh) 2016年6月21日
【#SPLYZAバスケ班】
— SPLYZA Teams (@SplyzaTeams) 2019年2月6日
◆NBAのリーグ全体の順位(勝率)
1.バックス(.750)
2.ウォリアーズ(.712)
3.ラプターズ(.704)
4.ナゲッツ(.698)
画像:シュートHEX MAP
この数字が高ければ勝てる、というのはありませんが、やはりシュートは大事です。
穴がなく、3Pの入るウォリアーズはパッと見でも凄い。 pic.twitter.com/qh0GAu9qcb
では、サッカーのxGの近年の具体的な進展について見てみましょう。xGプロットのパイオニアである11tegen11氏は2014年のワールドカップには既にツイートしています。
xGの最も直接的な使い道はストライカーやチームの攻撃の実力を測定することと、シュミレーションによる予測です。それまでは実際の得点を使って同様のことを行っていましたが、サッカーが少ない得点で競う競技であるという特性から、短期的にはノイズ(偏差)が大きい可能性があります。例えばミラクルレスターのマフレズはオーバーパフォーマンスだったと言われています。
xGによってストライカーの評価が始まると、次にチャンスメーカーの評価をしたいと思うようになりました。それがxAの始まりです。もともとはStatsBombのxGAssistのように、単にxGの値をアシストした選手にも割り当てる方法が普通でしたが、OptaのxAはある意味真のアシスト期待値で、全てのパスに関してアシストになる可能性を算出しています。
シュート、アシストと来ればそれ以前のポゼッションを評価する指標がほしいと思うのは当然でしょう。此処ではxGベースのポゼッション指標に関して3つ紹介します。まずはNils
Mackay氏のxGaddedに触れましょう。これは彼の修士課程での内容で、現在はOptaのデータアナリストとして働いています。個人的には2017年に行われたChance
Analyticsのデータビジュアル化コンペで優勝したCKの分析が印象に残っています。さてこのxGaddedという指標は、パスの開始地点と終了地点のxGの差を選手に割り当てます。従ってバックパスをすればマイナスの値にもなりえます。パスの種類をパラメータに組み込んだり、ドリブルの場合の指標を作ったり、ミスに対するペナルティの取り方によってモデルを改善していました。また興味深いのは、ゴールドゾーンと呼ばれるペナルティエリア内ゴールエリア幅のゾーンではシュートを、それ以外ではパスを選択した方が良いことがヒートマップで可視化されます。
Passmaps & xGplot for Colombia against Japan. #passmap #xGplot #autotweet pic.twitter.com/ions5yOHK8
— 11tegen11 (@11tegen11) June 19, 2018
次にxGChainです。これが恐らくも最も有名でしょう。シュートで終わったポゼッション連鎖(一連のポゼッション)に関与した選手全員にxGを割り当てます。なお、ポゼッション連鎖に関与した選手の中でシュートとアシストした選手を除いてxGを割り当てる指標、すなわちxGChainーxGーxGAssistをxGBuildupといいます。この指標の問題点は、後方で圧力のない中横パスを出した選手とシュートやアシスト、キーパスを出した選手が同じポゼッション連鎖ならば同様に値を得ることです。
そしてxGChainを拡張することを目的にAmerican Soccer
Analysisで導入されたのがxPGです。これはシュートで終わらなかったポゼッション連鎖についてもxGベースの指標で評価するものです。簡単に説明すると、ピッチ全体にxGの値を割り当て、ポゼッションの軌道によってポゼッション連鎖の指標を定義します。xGChainと同様に全ての選手に同様に値を割り当てるという問題点はありますが、試合中の全ての時間帯で指標を定義できるようになった点で大きな改善だと言えるでしょう。特にチームごとのxPGの値によって試合の時間帯ごとの優劣を可視化するGameFlowというプロットは興味深いです。
xPG GameFlow 2018 FIFA Men's World Cup: @HNS_CFF v @equipedefrance on 07/15/2018. #CRO #FRA #CROvFRA data via @StatsBomb pic.twitter.com/HpjiiGe3z4
— GameFlow (@GameFlowxPG) 2018年9月24日
ここ数ヶ月のxGの流れを見てみるとStatsBombのGK分析が挙げられるでしょう。少し前にxGはチャンスの質を評価する指標で、選手の実力やシュートの質は無視すると言いました。しかしこの分析では、従来のxGの定義をプレシュートとし、シュートの質をポストシュートとして取り扱っています。シュートを打たれても他の選手がブロックしたり枠外に外れたりします。ポストシュートでは実際にGKが対処しなければならない状況について分析しようとしています。さらに平面座標(xy)だけでなく、高さ(z)のデータ収集も始まったようなので要注目です。
機械学習とロジスティック回帰
それでは実装に向けて少し詳しく説明していきます。もしデータ解析に詳しい場合はGithubなどにコードが載っているので、検索してみてください。
xGモデルは、バズワードを使えばいわゆる機械学習を使います。xGモデルで一般的なのはロジスティック回帰を用いることです。参考までに、サポートベクターマシン(SVM)を用いているという記述も見たことがあります。またGarry
Gelade氏のOptaPro記事で、クロスの開始地点と終了地点の分析において条件付き推論ツリーを用いています。
サッカーとは得点数を競う競技で、得点を奪うアクションがシュートです。シュートがゴールに入れば1点、入らなければ0点です。このようにある確率で1、それ以外で0を取る確率変数はベルヌーイ分布に従うと言います。なお、この確率が一定でベルヌーイ試行を何度も繰り返すと、二項分布、多項分布という数学で習ったはずのものになります。
ただしシュートが入る確率は毎回一緒ではありません。様々なパラメータによって変化します。ロジスティック回帰はこのベルヌーイ分布と非常に相性が良いのです。
では、なぜxGの値が提供者によって異なるのでしょうか。まずはデータを集計している会社の違いや受け取っているデータ量の違いがあります。これは容易に想像できるでしょう。また先程述べた数理モデルの違いがあります。そしてロジスティック回帰を用いる場合でも違いが出ます。例えば足でのシュートとヘディングシュートの場合、データを全て場合分けすることもできますし、0と1のパラメータにすることもできます。また角度の取り方についても、シュート位置と両ポストでできる角度を使うことが多いようですが、他の取り方も可能でしょう。さらに全てのパラメータを単純に組み込むだけでなく、二乗の項や複数のパラメータの積の項も組み込むことができます。
予測とポワソン分布
xGを測定できたら次は活用です。11tegen11氏や彼が始めたBetween The
Postでは、優勝やチャンピオンズリーグ出場圏、降格争いのオッズを公開しています。この仕組みを理解するのに重要なのはポアソン分布です。
With Liverpool's dropped points, City are back to nearly 50% for the title.
— Between The Posts (@BetweenThePosts) 2019年2月6日
Taking all three points at Goodison Park would even give them the slightest of edges to win the title.#EFC #MCFC pic.twitter.com/TSTl4tcSt9
ポアソン分布とは離散確率分布の一種です。離散とはとびとびの値のことです。サッカーの得点は非負整数(0と正整数のこと。0,1,2,...)で、ポアソン分布の定義を満たします。負の値を取れないことで正規分布が歪むという解釈もできるでしょうか。
最初の方に示したxGプロットの下の方に、各チームの得点数の妥当性についてシュミレーションした結果がありました。この結果とポアソン分布(平均と分散は等しくラムダでされ、ラムダにxGの値を代入する)を見比べると、同様な分布であることがわかります。
ということは、残りの試合についてポアソン分布の変数を用いてシュミレーションを繰り返し行えば、オッズを計算できるでしょう。ホームとアウェイを区別しているのかなど詳細はわかりませんが、ポアソン分布を使っていることは間違いありません。
トラッキングデータを組み込む
最後に、データ分析の近未来についての私見で締めくくろうと思います。この記事の中盤で紹介したように、パスやポゼッションを評価するxGベースの指標があります。一方で、トラッキングデータを用いたパッキングレートという指標もあります。これはパスによって何人の相手を通過できたのかを計測します。この指標は2014年ワールドカップ準決勝ドイツ対ブラジルの試合を例に出すことが多いですが、xGも含めて従来のスタッツでは差があまり見えない試合の中で7-1という結果を最もよく説明しています。2018年のワールドカップのテクニカルレポートにもデータが少し掲載されており、今後の発展が期待される指標です。
このパッキングレートの使い道として考えられるのが、xGモデル自体への組み込みとxGベースの指標との融合です。例えば一般的にアシストがクロスよりもスルーパスの方が得点の可能性が高くなるのですが、こういったところにパッキングレートの入り込む余地があります。
パッキングレートを始め、トラッキングデータの活用は今後加速すると思われます。それは衛星によるGPSシステムの精度向上や、東京オリンピックを目処にした5Gの開始といった理由からです。人間が感知できないような時間のズレで、大量のデータを輸送できるようになれば、大きな革新が生まれることは間違いないでしょう。
著者プロフィール:Temma H. データアナリスト
1995年生まれのゆとりど真ん中。サッカーに関するデータ分析を趣味で独学しています。
・Twitter